이번 프로젝트에서 네이버 클라우드 플랫폼에서 제공하는 CLOVA OCR 기능을 활용해서 이력서 정보를 추출하려고 합니다.
구글 비전 AI 대신 클로바 OCR로 변경했는데, 그 이유는 클로바 OCR은 가로로 문자 추출이 가능해서 가공할 때 편리하고 한글 텍스트 인식이 잘 된다는 장점이 있어서 선택했습니다.
인식 모델은 Premium, 서비스 플랜은 General을 사용해서 월 100회 이하 호출까지 무료로 사용할 수 있는 서비스 타입을 사용했습니다.
OCR 과정
Naver CLOVA OCR의 동작 과정입니다.
이미지에서 텍스트를 찾고 기존의 템플릿과 분류하는데, 저는 General OCR을 사용할 예정이라 템플릿 과정은 생략됩니다.

클로바 OCR 사용법
https://www.ncloud.com/product/aiService/ocr
NAVER CLOUD PLATFORM
cloud computing services for corporations, IaaS, PaaS, SaaS, with Global region and Security Technology Certification
www.ncloud.com
이 링크를 통해 들어가면 상품 설명이 자세히 나와있습니다.
[이용 신청하기] 버튼을 클릭하면 간단한 회원가입을 통해 콘솔로 이동할 수 있습니다.

콘솔에서는 네이버 클라우드 플랫폼이 지원하는 많은 서비스를 사용할 수 있습니다.
저는 OCR을 사용할 것이기 때문에 [Service]-[검색]-[CLOVA OCR]로 들어갔습니다.
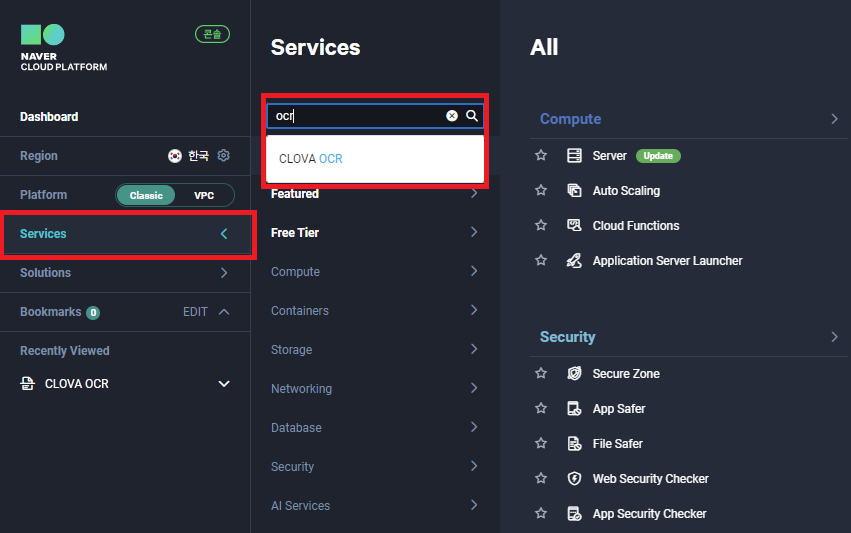
API를 사용하기 위해 먼저 도메인을 생성해야 합니다.
저는 [일반 도메인]을 선택하겠습니다.

이제 도메인 명, 코드, 언어, 타입 등을 선택합니다.
저는 이미 일반 타입을 생성해서 추가 생성이 안되는데, 리전당 1개만 일반 타입 생성이 가능하다고 합니다.
이때 서비스 플랜을 Free가 아닌 다른 타입으로 선택하면 기본요금이 부과됩니다.

생성된 도메인에서 [옵션]-[API Gateway 연동]을 클릭합니다.
Secret key를 생성하고 주소와 함께 다른 곳에 복사해 둡니다.

이제 코드로 연결하면 OCR을 사용할 수 있습니다.
파이썬으로 OCR 연결하기
네이버 클로바 OCR은 사용 가이드를 보면 코드도 자세히 나와있습니다.
그중 파이썬 코드 예제를 가져와서 사용하겠습니다.
저는 application/json 형식으로 사용했습니다.
import requests
import uuid
import time
import base64
import json
api_url = 'YOUR_API_URL'
secret_key = 'YOUR_SECRET_KEY'
image_url = 'YOUR_IMAGE_URL'
image_file = 'YOUR_IMAGE_FILE'
with open(image_file,'rb') as f:
file_data = f.read()
request_json = {
'images': [
{
'format': 'jpg',
'name': 'demo',
'data': base64.b64encode(file_data).decode()
# 'url': image_url
}
],
'requestId': str(uuid.uuid4()),
'version': 'V2',
'timestamp': int(round(time.time() * 1000))
}
payload = json.dumps(request_json).encode('UTF-8')
headers = {
'X-OCR-SECRET': secret_key,
'Content-Type': 'application/json'
}
response = requests.request("POST", api_url, headers=headers, data = payload)
print(response.text)
# inferText만 출력
# for field in response["images"][0]["fields"]:
# print(field["inferText"])
로컬에 있는 파일을 사용하기 위해 url 필드는 주석처리 했습니다.
위 코드에서 inferText만 따로 출력하도록 주석 처리된 부분을 해제하고 실행한 결과는 다음과 같습니다.


이 결과값은 각 요소의 x와 y 좌표를 함께 보내주는데, 이 좌표를 사용해서 y 좌표 값이 오차범위에 있는 경우 같은 줄로 판단하는 코드를 추가했습니다.
우선 이 결과 text를 json 파일로 만들고, 오차 범위는 5로 설정했습니다.
res = json.loads(response.text)
with open('result_json.json', 'w') as json_file:
json.dump(res, json_file, indent=4, ensure_ascii=False)
grouped_texts = {}
# y축 오차 범위
y_error_range = 5
for field in res["images"][0]["fields"]:
height = field["boundingPoly"]["vertices"][0]["y"]
infer_text = field["inferText"]
# 오차범위 이내의 같은 y축에 있는 값 같은 열로 취급하기
closest_height = next((h for h in grouped_texts if abs(height - h) <= y_error_range), None)
if closest_height is not None:
grouped_texts[closest_height].append(infer_text)
else:
grouped_texts[height] = [infer_text]
result_string = ''
for height, texts in sorted(grouped_texts.items()):
result_string += ' '.join(texts) + '\n'
# 결과 출력
print(result_string)
결과는 다음과 같습니다.
아래 예시 파일은 jpg 파일임에도 선명하게 한글 및 영어를 인식하는 것을 확인할 수 있습니다.


'졸업프로젝트' 카테고리의 다른 글
| [Python] Google Vision AI OCR 텍스트 인식 구현 + pdf에서 이미지로 변환 (1) | 2023.11.24 |
|---|