Google Vision AI가 제공하는 OCR(광학 문자 인식) API를 사용해서 파이썬으로 이미지에서 텍스트를 추출하는 코드를 구현해 보겠습니다.
Vision AI에서 제공하는 이 api는 이미지 파일에서 텍스트를 추출하는 기능만 제공하므로 pdf로 변환해서 추출하는 코드도 구현할 예정입니다.
이미지에서 텍스트 추출하기
Google Vision AI 시작하기
https://cloud.google.com/vision?hl=ko
Vision AI | Google Cloud
AutoML Vision을 사용하여 이미지에서 유용한 정보를 도출하거나 선행 학습된 Vision API 모델을 사용하거나 Vertex AI Vision으로 컴퓨터 비전 애플리케이션을 만들어 보세요.
cloud.google.com
위의 링크를 들어가서 Vision AI 무료로 사용해 보기를 클릭합니다.
약관 동의, 주소, 결제 정보를 입력한 후 콘솔창으로 이동합니다.
이 서비스는 무료로 3개월 동안 사용할 수 있습니다.
OCR api를 사용하기 위해서 프로젝트를 생성하고 키를 생성해서 json 파일로 폴더에 저장해야 합니다.
저는 이전에 생성한 프로젝트가 있어서 [My First Project]가 보이지만, 저 버튼을 클릭해서 새로운 프로젝트를 만들어 주겠습니다.
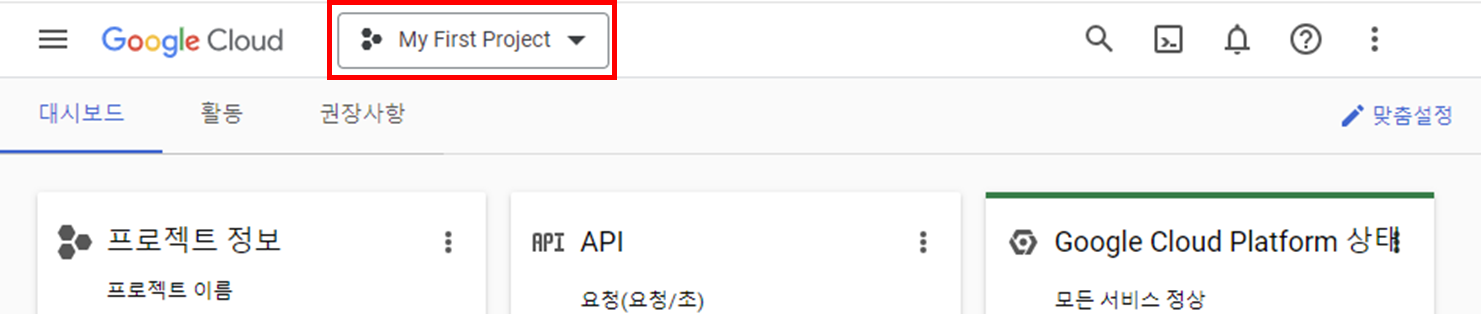
프로젝트 이름을 입력하고 [만들기] 버튼을 클릭해 주세요.
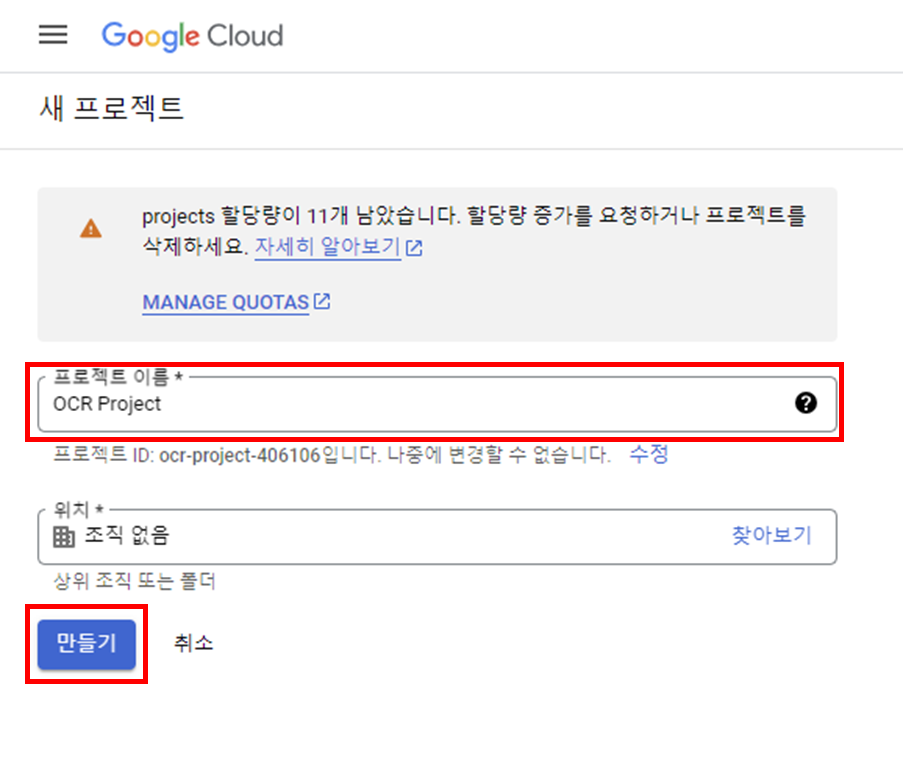
이제 서비스 계정을 만들고 키를 받아야 합니다.
왼쪽 상단 [메뉴바] - [IAM 및 관리자] - [서비스 계정] - [+ 서비스 계정 만들기]를 선택하고 새로운 계정을 만들어 주세요.
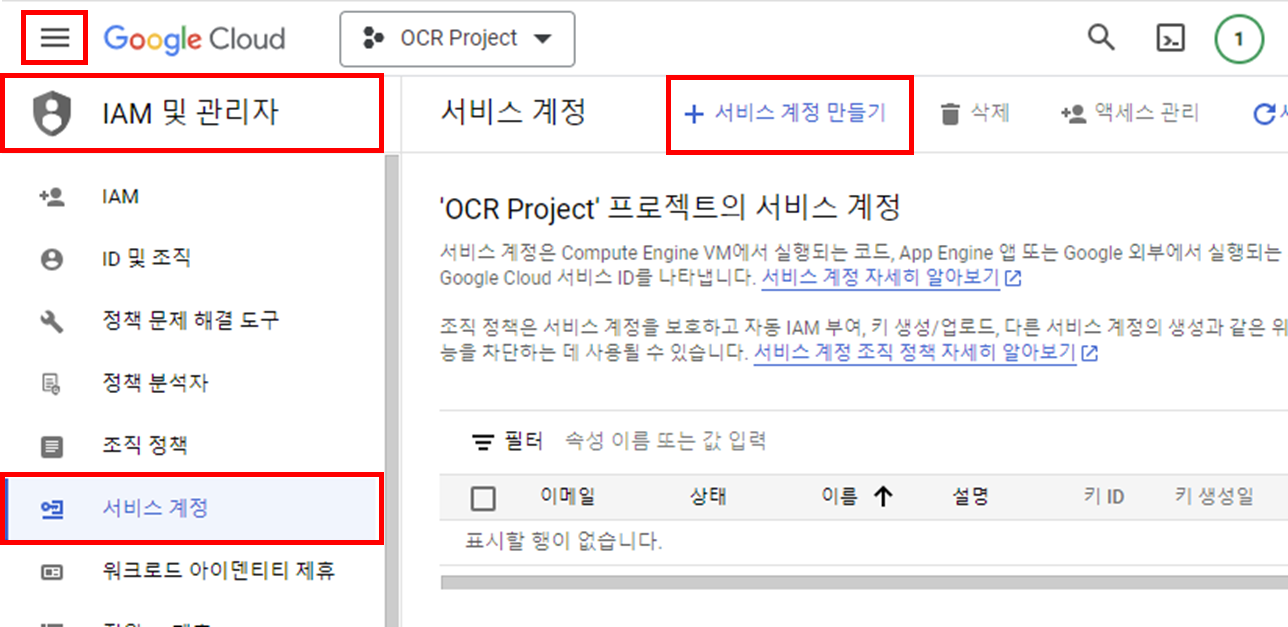
저는 테스트용으로 만드는 프로젝트라서 서비스 계정 이름과 서비스 계정 ID만 입력했습니다.
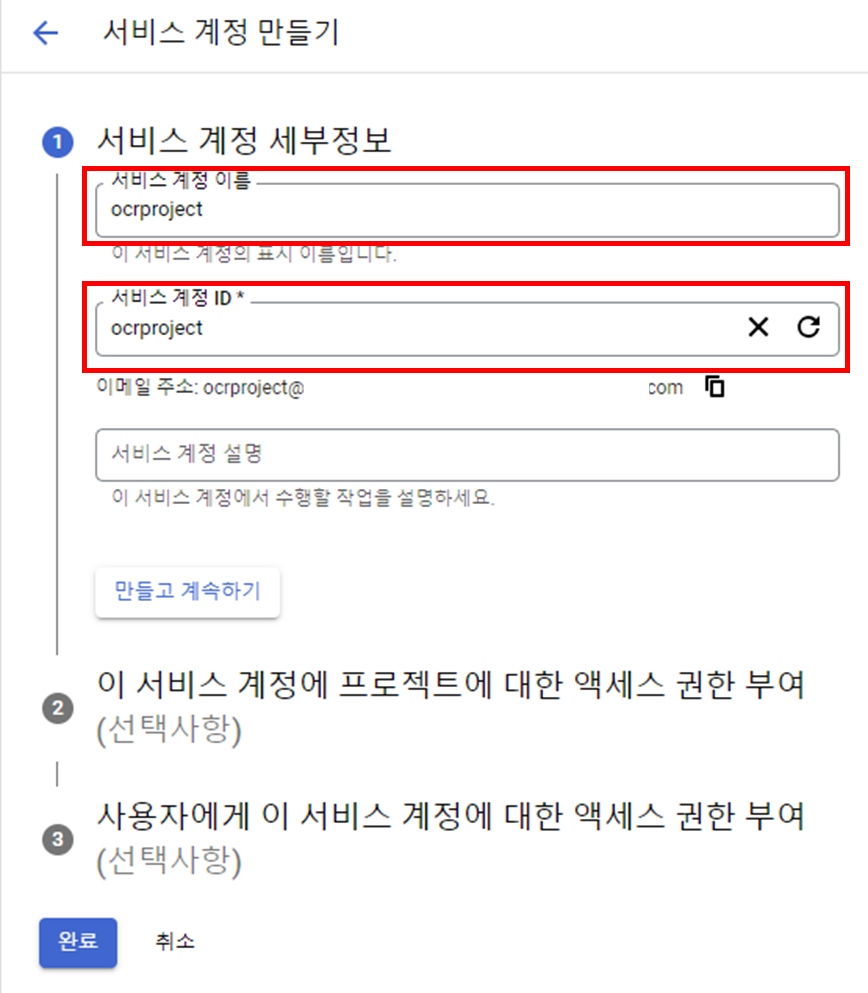
이제 키를 생성하겠습니다.
[작업] - [키 관리]를 클릭해 주세요.
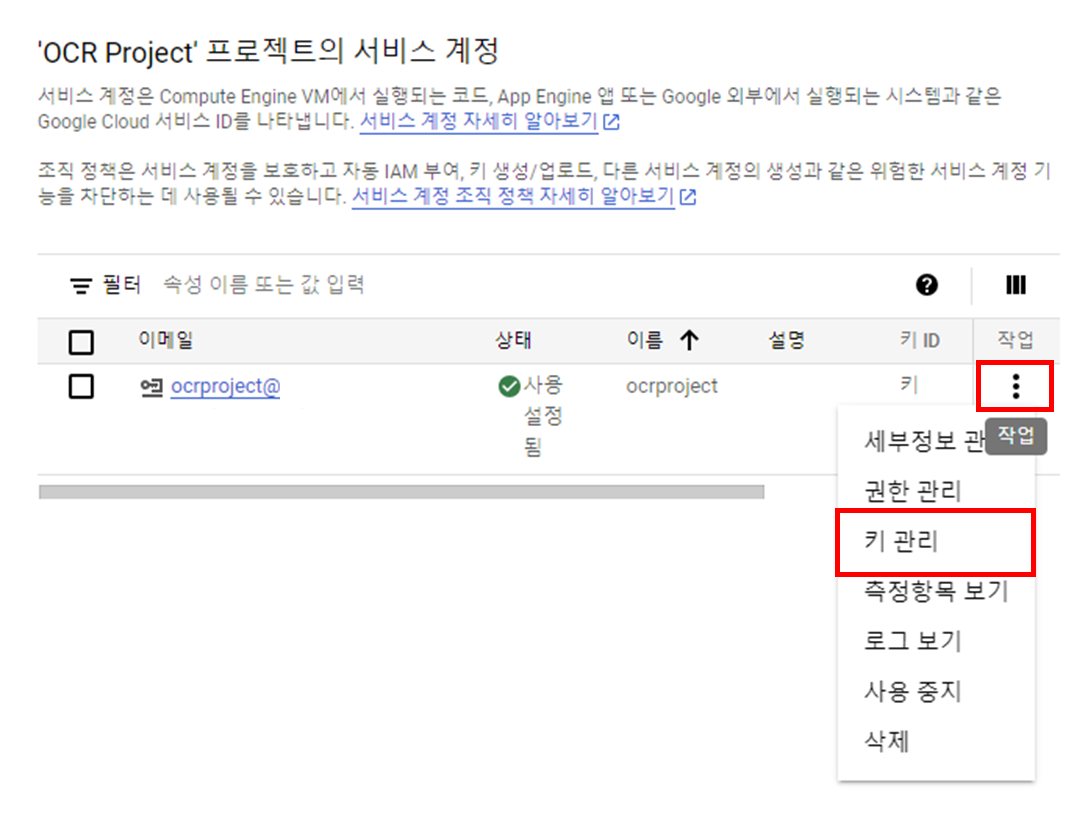
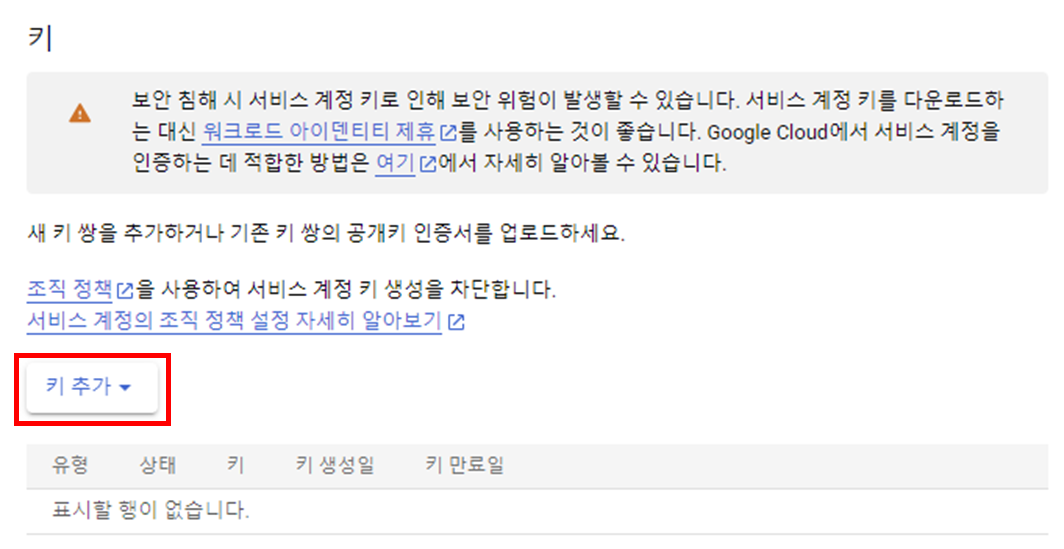
[키 추가] 버튼을 클릭하고, [새 키 만들기]를 클릭합니다.
그럼 모달이 뜨는데 키 유형은 JSON으로 선택하고 [만들기] 버튼을 클릭하면 json 파일이 다운로드됩니다.

개발 환경 구성하기
이제 필요한 라이브러리를 설치하겠습니다.
cmd 명령 프롬프트에 다음 명령어를 입력해서 google-cloud-vision 라이브러리를 설치해 주세요.
$ pip install --upgrade google-cloud-vision
Python 코드 작성하기
필요한 패키지를 import 해줍니다.
import os
import io
from google.cloud import vision
아까 다운로드한 json 파일은 파이썬 파일과 동일한 디렉터리에 넣어주세요.
Google Vision API에 액세스하기 위한 클라이언트 인터페이스를 생성하는 방법입니다.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./다운받은JSON파일.json"
파이썬 파일이 있는 폴더에서 cmd를 열어 다음 명령어를 실행해서 임시 환경 변수를 설정해도 되는데 저는 이 방법으로는 액세스 할 수 없었습니다.
$ set GOOGLE_APPLICATION_CREDENTIALS="./다운받은JSON파일.json"
그리고 이미지를 넣어둘 img 폴더와 변환한 파일을 담을 text 폴더를 만들었습니다.
코드 부분은 다음과 같습니다.
# 클라이언트 인터페이스
client = vision.ImageAnnotatorClient()
# 읽어올 파일
filenames = os.listdir('./img')
for filename in filenames:
path = os.path.join('./img', filename)
with io.open(path, 'rb') as image_file:
# 파일 읽기
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
with open('./text/' + filename + '.txt', 'w') as f:
# txt 파일로 텍스트 인식 결과 저장하기
f.write(texts[0].description)
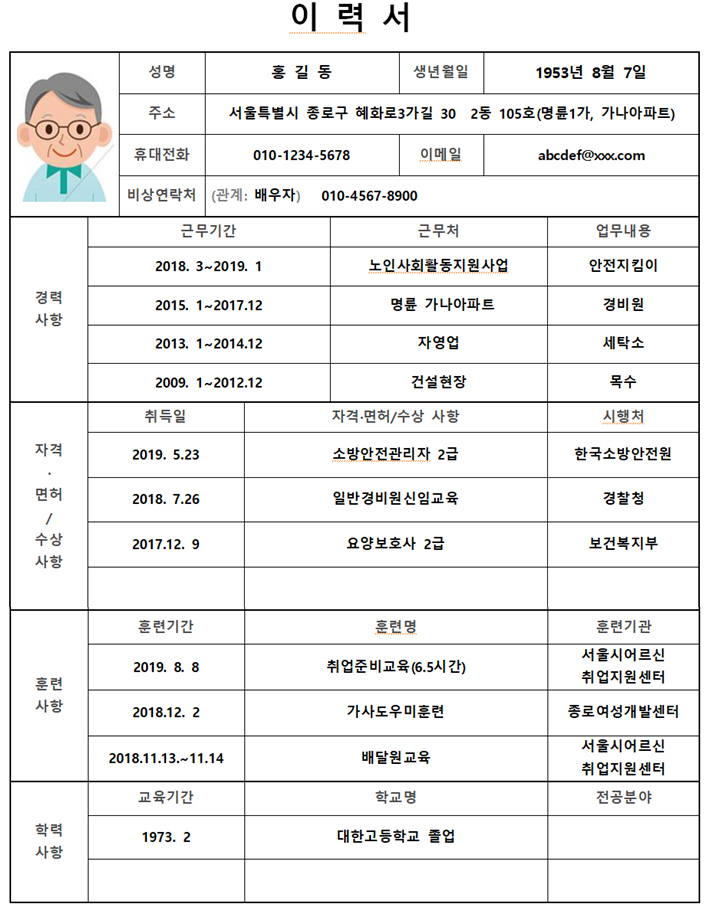
결과
결과를 보면 왼쪽부터 시작해서 위에서 아래 방향으로 인식하여 글자를 추출하는 것을 볼 수 있습니다.

PDF 파일에서 이미지 파일로 변환하기
PyMuPDF 라이브러리 설치
pdf에서 이미지로 변환하는 라이브러리는 다양하지만 저는 PyMuPDF 라이브러리를 사용했습니다.
pip로 설치만 하면 바로 사용할 수 있어서 간편합니다.
$ pip install PyMuPDF
설치 후에 패키지를 import 합니다.
import fitz
파일명에서 확장자 분리하기
기존 코드에서 pdf 파일인 경우 처리를 할 수 있도록 파일명을 분리하는 코드를 추가했습니다.
os.path.splitext() 함수를 사용하면 됩니다.
filebasename, filetype = os.path.splitext(filename)
이제 filetype이 .pdf인 경우만 PyMuPDF 라이브러리를 이용해서 png 파일로 바꿔주겠습니다.
if filetype == '.pdf':
# PyMuPDF로 파일 열기
newFile = fitz.open('./img/' + filename)
for i, page in enumerate(newFile):
img = page.get_pixmap()
img.save(f'./img/{filebasename}.png')
filename = filebasename + '.png'
if i == 0:
break
저는 첫 페이지만 변환해서 사용하기 위해 if 문을 추가했습니다.
모든 페이지를 png로 변환하려면 if break 코드를 삭제하고 다음과 같이 코드를 바꾸면 됩니다.
img.save(f'./img/{filebasename}_{i}.png')
코드 전문
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./다운받은JSON파일.json"
import io
from google.cloud import vision
import fitz
# 클라이언트 인터페이스
client = vision.ImageAnnotatorClient()
# 읽어올 파일
filenames = os.listdir('./img')
for filename in filenames:
filebasename, filetype = os.path.splitext(filename)
if filetype == '.pdf':
# PyMuPDF로 파일 열기
newFile = fitz.open('./img/' + filename)
for i, page in enumerate(newFile):
img = page.get_pixmap()
img.save(f'./img/{filebasename}.png')
filename = filebasename + '.png'
if i == 0:
break
path = os.path.join('./img', filename)
with io.open(path, 'rb') as image_file:
# 파일 읽기
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
with open('./text/' + filename + '.txt', 'w') as f:
# txt 파일로 텍스트 인식 결과 저장하기
f.write(texts[0].description)
print(f)
결과
pdf에서 png로 바꾼 파일을 텍스트 인식 후 txt 파일로 저장했습니다.


'졸업프로젝트' 카테고리의 다른 글
| [Python] NAVER CLOVA OCR로 이미지에서 글자 추출하기 (0) | 2024.05.21 |
|---|